
Improving the performance of vec
Continuing from the last post, one of the things I’ve worked on for Clojure 1.7 is improving the performance of vec, which takes a collection and returns a vector. This work is captured in CLJ-1546. The work in this ticket is included in Clojure 1.7.0-alpha5.
The vec patch has the same optimization for being passed a vector with effectively the same optimization (returning a new vec with meta cleared) as the set patch from yesterday. After that, everything gets tricky.
Some of the code involved here was created very early in Clojure’s development and vec itself is defined quite early during core.clj bootstrapping before defmacro and thus before and, or, and lots of other important things. Because of that a lot of the former logic was shunted into Java in the LazilyPersistentVector (hereafter LPV) static methods, which subsequently called into various PersistentVector (hereafter PV) factory methods.
PV is interesting in that if you happen to have no more than 32 elements, there is a special fast construction path where you can essentially make the root node directly from an array without even using transient conj. A lot of the prior code in LPV was concerned with detecting this case and exploiting it for performance and I have taken it even farther.
One useful thing I did in understanding things a bit better was to hack some code into vec to record the type and size of actual collections passed into this function, then run this instrumented version of Clojure on various code bases. Here’s what I recorded on a few examples (these are the equivalent of running “lein test” in a project then getting an output at the end). The last column shows the path these cases will go down in the final patch, which I haven’t explained yet. All the classes are from clojure.lang, except ArrayList which is Java.
Clojure itself
| Concrete coll | count | min | 90%-ile | max | path |
|---|---|---|---|---|---|
| ArrayList | 9451 | 0 | 86 | 380 | Iterable |
| PersistentVector | 1197 | 0 | 98 | 271 | IPersistentVector |
| LazySeq | 813 | 0 | 3 | 58 | ISeq |
| PersistentHashSet | 582 | 0 | 1 | 4 | Iterable |
| Cons | 449 | 2 | 8 | 53 | ISeq |
| PersistentVector$ChunkedSeq | 7 | 1 | 1 | 1 | ISeq |
| null | 1 | 0 | 0 | 0 | array |
Mostly ArrayList and PersistentVector. I think the ArrayLists are actually coming out during compilation - I did some investigation on it, but it was a while ago and I’ve forgotten the details. Remember, PV is the one where we can dramatically reduce the time so it’s interesting to see this so prominent.
Prismatic schema
| Concrete coll | count | min | 90%-ile | max | path |
|---|---|---|---|---|---|
| LazySeq | 2066 | 0 | 2 | 16 | ISeq |
| ArrayList | 1135 | 0 | 4 | 14 | Iterable |
| Cons | 186 | 3 | 8 | 21 | ISeq |
| PersistentHashSet | 95 | 0 | 1 | 1 | Iterable |
| PersistentList | 9 | 2 | 2 | 2 | ISeq |
No vectors at all here, but lots of LazySeqs and still some ArrayList. Note also that every single collection passing through vec was less than 32 elements.
Instaparse
| Concrete coll | count | min | 90%-ile | max | path |
|---|---|---|---|---|---|
| PersistentVector | 23424 | 0 | 1 | 18 | IPersistentVector |
| LazySeq | 4828 | 0 | 1004 | 1415 | ISeq |
| ArrayList | 1808 | 0 | 4 | 48 | Iterable |
| PersistentVector$ChunkedSeq | 344 | 1 | 56 | 63 | ISeq |
| Cons | 63 | 4 | 8 | 13 | ISeq |
| PersistentHashSet | 29 | 0 | 1 | 18 | Iterable |
| null | 4 | 0 | 0 | 0 | array |
The same set of types here as in the Clojure build, but we see a crazy number of small vectors passing through vec - fertile ground for a speed boost.
Aleph
| Concrete coll | count | min | 90%-ile | max | path |
|---|---|---|---|---|---|
| ArrayList | 5328 | 0 | 4 | 29 | Iterable |
| LazySeq | 2401 | 0 | 6 | 17 | ISeq |
| Cons | 1010 | 2 | 12 | 21 | ISeq |
| PersistentHashSet | 383 | 0 | 5 | 19 | Iterable |
| PersistentVector | 338 | 0 | 8 | 19 | IPersistentVector |
| ChunkedCons | 40 | 8 | 8 | 8 | ISeq |
Lots of sequence-y things here, but everything is small.
Trapperkeeper
| Concrete coll | count | min | 90%-ile | max | path |
|---|---|---|---|---|---|
| LazySeq | 105071 | 0 | 2 | 10 | ISeq |
| ArrayList | 3871 | 0 | 4 | 26 | Iterable |
| Cons | 502 | 2 | 8 | 32 | ISeq |
| PersistentHashSet | 495 | 0 | 3 | 7 | Iterable |
| PersistentVector | 350 | 0 | 9 | 10 | IPersistentVector |
| PersistentVector$KeySeq | 141 | 2 | 3 | 3 | ISeq |
| PersistentVector$ChunkedSeq | 50 | 1 | 1 | 2 | ISeq |
| null | 14 | 0 | 0 | 0 | array |
| IteratorSeq | 4 | 1 | 1 | 1 | ISeq |
| ArraySeq | 2 | 1 | 1 | 1 | IReduceInit |
Again, lots of small sequences.
For me, this helped give me an idea of what the data looked like. We want to minimize the number of branches in the code to improve inlining so we want to group cases together that will have a common implementation - those that can directly reduced, or walked as seqs or iterators.
After a lot of experimentation, I wound up with the following cases:
- IPersistentVector - if it’s already a vector, remove meta and return a new instance. This happens a lot as seen above and is now a fast constant time operation instead of a linear time operation.
- IReduceInit - if the collection can reduce itself, do so by conj’ing into a transient vector (effectively the same as
into). PersistentList did not show up in the data above but is handled by this case, as are a few other Clojure collections (likely more in the future). - ISeq - taking into account that small seqs are common, traverse the seq and add elements into a pre-allocated array. If the number of elements is less than or equal to 32, copy the read elements into a correctly sized array and construct the PersistentVector directly. If larger than 32, make the vector transient and continue conj’ing into it. If something is both a seq and iterable, there is no point in building an iterator over the seq - it’s going to be built regardless so we might as well use it directly.
- Iterable - this case handles Clojure maps, sets, and Java collections like ArrayList. Because ArrayList is so prevalent, and has the ability to extract an array directly for use there is a special case specifically for this type. Otherwise, we again use transients and walk the iterator. I experimented with the array collection trick here too but it did not seem to help.
- Array - in all other cases, fall back to using RT.toArray() to extract or construct an array, then if possible use the small array construction trick.
I ran a large set of tests for this ticket, too much to include directly but you can see the full data here. For each collection type I tested a range of sizes (generally 4, 16, 64, 256, and 1024 which seemed to largely cover the spread in the data above). The columns included are the time to use (into [] coll) and (vec coll) in 1.7.0-alpha4, then the time to do vec with the patch.
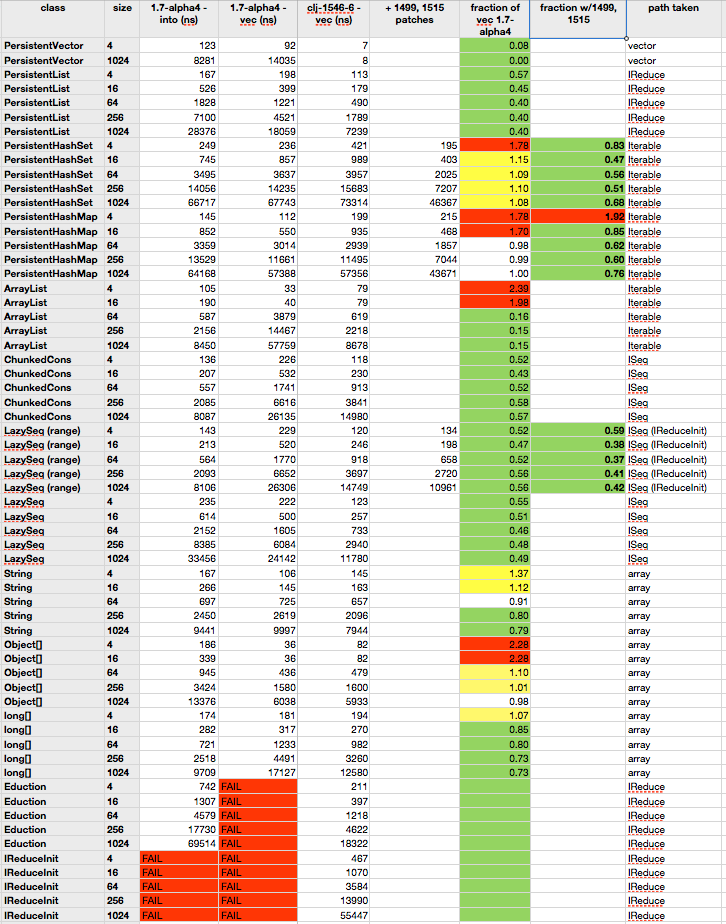{kind=link}
The next column considers two additional patches that interact with these changes. The first, CLJ-1499, provides new Iterators for PersistentHashSet and PersistentHashMap that directly walk the data structure rather than first creating an intervening seq. The second, CLJ-1515, is an optimized version of range that makes range seqs directly reducible (thus shifting them to the generally faster IReduceInit case).
The next two columns divide the time with the patch by the original vec time, so 1.0 means no change, less than 1.0 means faster, and more means slower. The second column shows the fraction updated when CLJ-1499 and CLJ-1515 are included. CLJ-1603 also makes cycle, iterate, and repeat directly reducible but I didn’t time that here.
As we look through the numbers it’s clear that overall, the times are substantially improved:
- A 1024 element vector drops from 14 microseconds to 8 nanoseconds - 1000x improvement
- Persistent lists of all sizes are half or less of the time
- Persistent sets of all sizes are as much as half of the time
- All but the smallest persistent maps are significantly faster (this is a rare case anyhow)
- ArrayList is way faster when >32 but about twice as slow for the small lists. Given the frequency of this case, I spent quite some time on it. I believe that adding an explicit case for it would cut off the extra checks and make this faster again but at the expense of everything else. Given the size of the absolute values involved, I decided to leave as is.
- All kinds of sequences are about twice as fast - those that are reducible even better.
- Strings (not seen in the data) are slower for small strings and faster on big strings. Not an important case.
- Arrays are kind of a mixed bag. Object arrays are definitely slower for small arrays and about the same for bigger - there is just more overhead with more conditionals than in the past. But again, this is not a critical use case. Primitive arrays are faster.
- And finally, the new Eduction and IReduceInit cases work where they threw exceptions before.
There were a lot of things to balance with this ticket and early versions had way more cases and performance wasn’t too great. Right now, I think it’s definitely a significant improvement. I’m still bothered a bit by the small ArrayLists but we’ll talk about that in screening I suspect.